- شروع کننده موضوع
- #1
Yabançı
کاربر نیمهحرفهای

- ارسالها
- 255
- امتیاز
- 388
- نام مرکز سمپاد
- طلایه داران
- شهر
- لاچین
- رشته دانشگاه
- JLE
چرا همه باید برنامهنویسی یاد بگیرند ؟
به نظرم فرقی نمیکنه چند سالتون باشه ، تو چه رشتهای تحصیل میکنید و یا چه آیندهی شغلی واسه خودتون در نظر گرفتید ، یادگرفتن برنامهنویسی میتونه به شما نحوهی درست فکرکردن رو یاد بده ، علاوه بر این برنامهنویسی دید شما رو نسبت به مسائل وسیعتر میکنه.
چرا پایتون؟
اگه سمپادی باشین به احتمال زیاد با چند تا زبانبرنامهنویسی آشنا هستید و احتمالا مبانی یکی از زبانها مثل سی یا سیپلاسپلاس یا بیسیک رو بلدید ، یادمه ما تو دورهی دبیرستان cpp رو یاد میگرفتیم که به نظرم بدترین گزینه برای یاددادن به یک دانشآموز بود چون زبان های سطح پایین و میانی اصلا برای کاربرد های علمی و عمومی مناسب نیستند بعدها آموزشوپروش نشون داد که همیشه گزینه بدتری هم وجود داره و یک زبان تجاری و تاریخگذشته و کمکاربرد و ضعیف به نام vb رو بهمون یاد داد.
من به دلیل علاقم به برنامهنویسی با زبانهای برنامهنویسی زیادی کار کردم و برنامه نوشتم از سی و سیپلاسپلاس و جاوا گرفته تا زبونهای تحت وب مثل پیاچپی و زبونهای فریمورک دات نت مثل سیشارپ و ... ، در بین این زبان ها تا چند ماه پیش جاوا به عنوان انتخاب اصلیم برای کارهای کوچیک و شبهعلمیم بود مثلا یادمه وقتی کتاب ساعتساز نابینای داوکینز رو میخوندم باهاش پروژه تفریحی فرگشت-کلمات رو شبیهسازی کردم.
تو دانشگاه به صورت اجباری با متلب آشنا شدم نفرتانگیزترین زبان ممکن! به معنای واقعی از ساختارش حالت تهوع میگرفتم کتابخونه های بسته و تجاری! البته دقیقا مطابق با ساختار علمی ایران!
تا اینکه پایتون رو شناختم! به معنای واقعی کلمه فوقالعاده هست ، پایتون زبان اول برنامهنویسی هست که تو اکثر کالج های آمریکا یاد میدن و همچنین شرکتهایی مثل گوگل و یاهو و ناسا پروژههای زیادی رو تو این زبان پیاده کردند. پایتون آزاد و سریع و آسون و سطحبالا و قابلحمل و زیبا و رایگان هست.
نمیخوام در مورد تاریخچه پایتون بگم میتونید اینجا بخونید : https://en.wikipedia.org/wiki/Python_%28programming_language%29
* واسه اجرای کدهام از سایت https://wakari.io استفاده میکنم که مفسر آنلاین کد پایتون هست(فوقالعاده نیست!؟) ، شما هر کجا دلتون خواست میتونید کداتون رو اجرا کنید.
طرح مسئله : الان به سرم زد دوباره فیلم «One Flew Over The Cuckoos Nest» رو ببینم و چون تصمیم گرفتم یکمی انگلیسیم رو تقویت کنم زیرنویس انگلیسی فیلم رو هم دانلود کردم اما از اونجایی که زبان انگلیسی من خوب نیست خیلی دلم میخواد یه ترجمهنصفه و نیمه هم از زیرنویسها یه جایی داشته باشم.
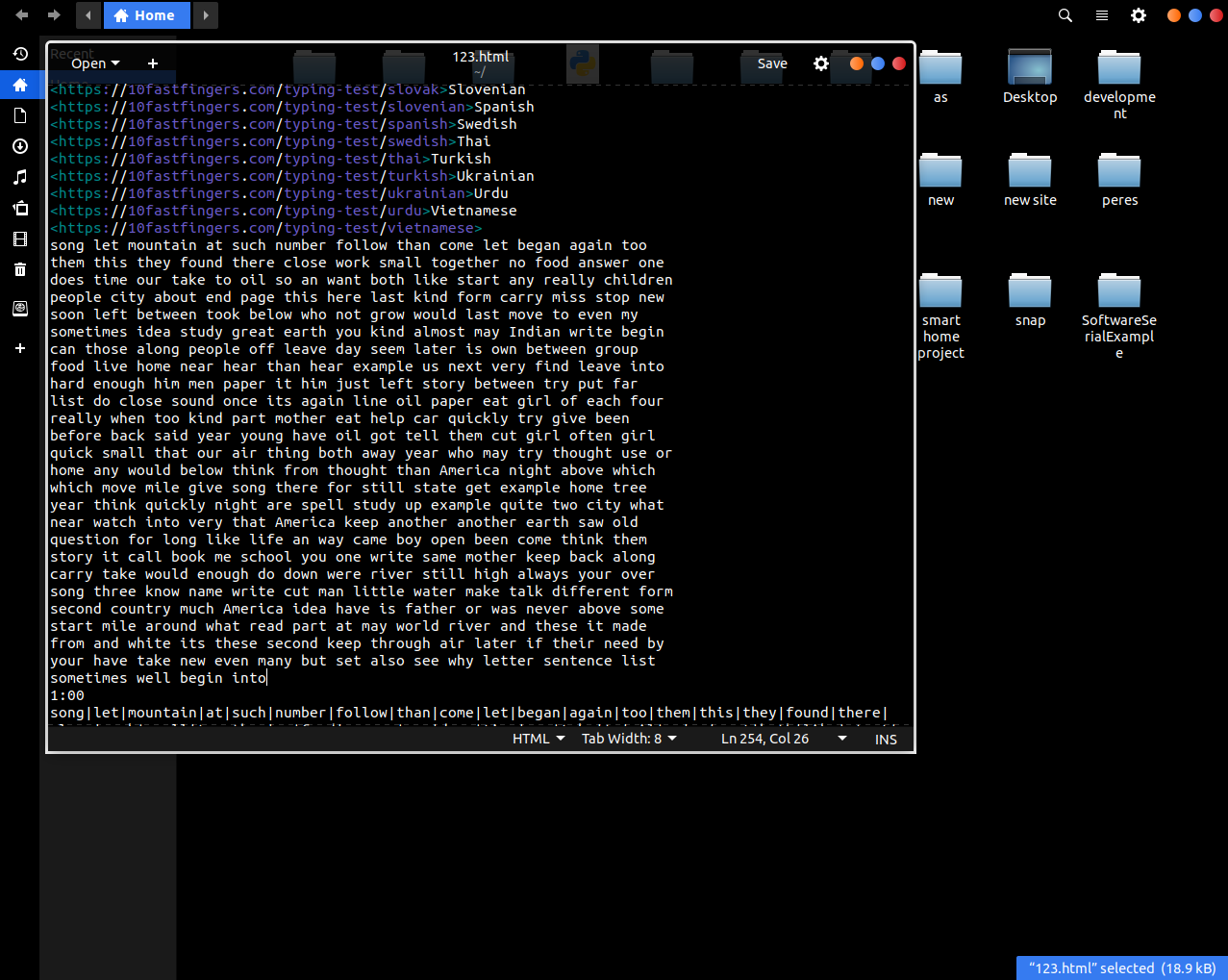
حل مسئله : زیرنویس فیلم یک فایل متنی با فرمت srt هست ، من فایل زیرنویس انگلیسیمو با یه ویرایشگر متن (مثل notepad) باز میکنم بزار اسکرین شاتش رو هم بزارم!

حالا باید ساختار فایل رو درک کنیم ، اگه دقت کنید کلا فرمتش اینطوری هست که هر کدوم از بخش ها یه شماره داره تو سطر بعدیش زمان شروع و پایان نمایش اون بخش بعد متن اون بخش رو داریم و بعدش هم یک سطر خالی.
یعنی هر قسمت زیرنویس این شکل رو داره :
...
شماره بخش
زمان شروع نمایش --> زمان پایان نمایش
متن جمله انگلیسی
سطر خالی
...
من میخوام همچین چیزی داشته باشم :
...
شماره بخش
زمان شروع نمایش --> زمان پایان نمایش
متن جمله انگلیسی
متن جمله ترجمهشده
سطر خالی
...
خوب وارد اکانتم در سایت wakari میشم و به کمک ابزار های پنل چپ (مخصوص مدیریت فایلها) یه پوشه واسه پروژه میسازم و زیرنویس رو هم آپلود میکنم تو همون پوشه :

تو wakari باید کدهامون رو تو یه notebook بنویسیم پس با گزینه new notebook یه دفترچه جدید میسازیم ، میتونیم بنویسیم 1+1 بعد اجراش کنیم تا ببینیم کار میکنه یا نه :

خوب حالا آمادهایم که کار رو شروع کنیم.
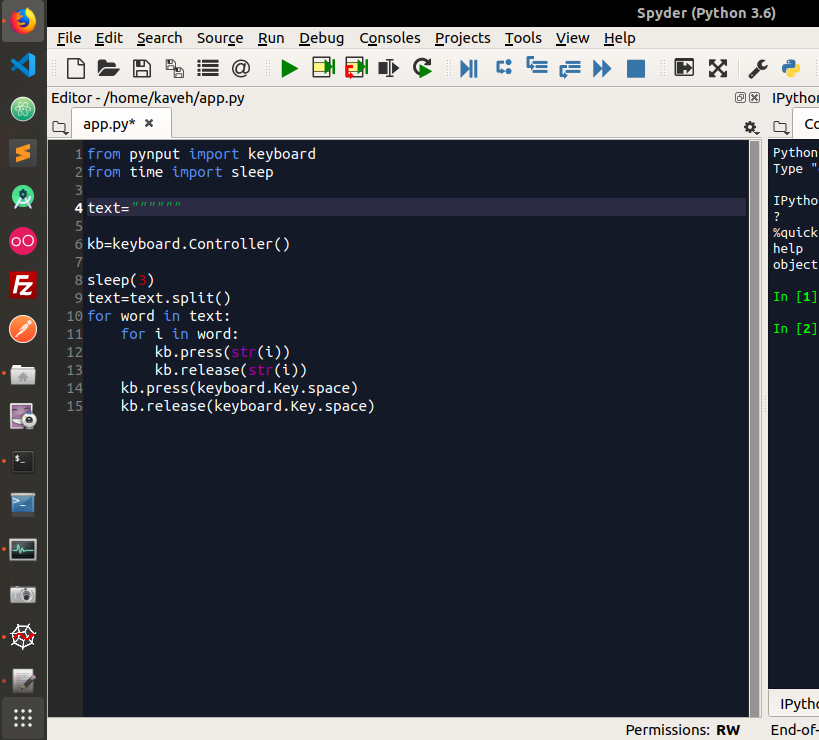
اول باید فایل زیرنویس رو بخونیم واسه خوندن فایل متنی یه تابعی هست تو پایتون به شکل زیر :
[ltr]open (name , mode , buffering)[rtl]
این تابع سه تا آرگومان داره که name آدرس و اسم فایل هست ، mode کاری هست که میخوایم رو فایل انجام بدیم مثلا خوندن یا نوشتن و بافرینگ هم بافرینگ فایل رو کنترل میکنه!
خوب مورد دوم و سوم اختیاری هستند و کلا نیاز نداریم از مورد سوم استفاده بکنیم واسه همین توضیحش نمیدم.
در برنامه نویسی یک نوع متغیر وجود داره به نام رشته یا string که شامل یه تعداد کاراکتر پشت سر هم هست.ما رشته ها رو داخل کوتیشن نشون میدیم مثلا اینطوری : "python"
تو پایتون میشه با تابع print یک رشته رو نشون دارد مثلا اینو ببینید:

یادتون باشه تو wakari کد شما به سلول های مختلفی تقسیم میشه که میتونید با گزینه ران فقط یک سلول رو اجرا کنید ولی برای اجرای تمام کد باید از قمست cell گزینه run all رو بزنید.
تو رشته ها بعضی کاراکترهای ویژه هستند مثل سطر بعدی و ... که برای نشون دادنشون از بکاسلش استفاده میکنیم.با فرمت "x\" که ایکس نشون دهنده کاراکتر ويژمون هست فرض کنید یه رشتهای داریم که توش کوتیشن داریم اینطوری میتونیم نشونش بدیم :

یا مثلا برای یک رشته چند سطری میتونیم اینکارو بکنیم :

برای اینکه به پایتون بگیم که بکاسلش نشانهی کاراکتر خاص نیست و منظورمون خود بک اسلش هست میتونیم یه r پشت رشته بزاریم که به معنی raw string یا رشته خام هست این دستورات رو با دستورات قبلی مقایسه کنید :

حالا برگردیم سراغ تابع open و آرگومان هاش ، آرگومان اسم فایل اینطوری میشه :
[ltr]name = "/user_home/w_sadiq/subtitle/ofotcn.srt"[rtl]
به آدرس فایل دقت کنید که sadiq اسم یوزر من تو wakari هست و شما باید یوزر خودتون رو بزنید یا مثلا اگه کد پایتونتون رو تو ویندوز اجرا کنید همچین آدرسی میشه :
[ltr]name = r"c:\subtitle\ofotcn.srt"[rtl]
آرگومان مدش هم اینطوری میشه:
[ltr]mode = "r"[rtl]
که به معنی خوندن هست.
با دستورات زیر فایل رو میریزیم تو متغیر file :

خوب متغیر file در واقع مثل رشته و عدد نیست و یک شی یا object هست.میتونیم با دستور زیر متن فایل رو بخونیم و بریزیم تو یک متغیر :
[ltr]subtitle_text = file.read()[rtl]
با دستور print میتونیم رشته subtitle_text رو ببینیم :

کار بعدی که میخوام بکنم اینه که هر قسمت زیرنویس رو جدا کنم و یه آرایه از این قسمتهای زیرنویس بسازم.قبلا بهتون گفتم که سطر بعدی رو تو یک رشته به شکل "n\" نشون میدیم ، این نحوه واسه سیستمهای یونیکس بیس هست ولی تو ویندوز از دو کاراکتر "r\n\" استفاده میکنیم.میتونید اینطوری تصور کنید که تو آخر هر سطری این کاراکتر ها وجود دارند ولی دیده نمیشن، حالا میتونیم با استفاده از تابع split قسمتهای بین سطرهای خالی زیر نویس رو جدا کنیم ، حالا به طور مثال میتونم قسمت 56ام زیرنویس رو جدا بکنم و نمایش بدم :

یکی از قدرت های پایتون ماژول ها یا کتابخونه های گسترده و غنی اون هستند ، ماژول ها رو میشه بستههای توابع آماده در نظر گرفت برای مثال کتابخانه استاندارد math شامل توابع ریاضی مثل توابع مثلثاتی و ... هست.با یه جستوجوی ساده میتونید ماژولهای مختلف ترجمه رو پیدا کنید.من میخوام از ماژول goslate استفاده کنم که میتونید document های مربوط به این ماژول رو تو این آدرس بخونید:
http://pythonhosted.org/goslate/
برای نصب این کتابخانه کافی هست تو کنسول shell سایت wakari این دستور رو وارد کنید:
[ltr]pip install goslate[rtl]

برای استفاده از یک ماژول باید به این روش اون رو import بکنید:
[ltr]import modulename[rtl]
این هم روش استفاده ازش :

خوب اینجا باید حواسمون باشه که اگه بخوایم همهی چند صد خط زیرنویس رو یکییکی بفرستیم به سرور گوگل ترنسلیت و ترجمشو بگیریم گوگل تشخیص میده که این کار یک آدم نیست بلکه کار یک برنامه هست و دسترسی بهش رو واسه شما میبنده.متاسفانه من حواسم نبود و در نتیجه گوگل کلا آدرس ip سایت wakari رو بن کرد!!
روش درست اینکار به نظرم این بود که همهی زیرنویس ها رو ترکیب میکردم و تو یک درخواست میفرستادیم به مترجم گوگل نه درخواست های متوالی یا حداقل بین درخواستهایی که برای ترجمه به سرور گوگل میفرستادم یکمی تاخیر زمانی قرار میدادم ، در هر حال به اشتباه یه نوع حمله denial of services رو سرور های گوگل انجام دادیم!
خوب میریم سراغ راه حل بعدی!
از اونجایی که از مترجم گوگل محروم شدم میریم سراغ مترجم bing متعلق به مایکروسافت با ماژول mstranslator که میتونید داکیومنتاش رو تو لینک زیر پیدا کنید :
https://pypi.python.org/pypi/mstranslator
برای نصبش تو کنسول shell سایت wakari این دستور رو وارد کنید:
[ltr]pip install mstranslator[rtl]
خوشبختانه ماژول مایکروسافت تا یکمیلیون کاراکتر رو رایگان ترجمه کنید برای استفاده ازش باید در سایت مایکروسافت نرمافزارتون رو ریجستر کنید و کلید ارتباطی بگیرید.
این لینک مرحلهبه مرحله یاد داده چیکار باید کرد :
http://blogs.msdn.com/b/translation/p/gettingstarted1.aspx
بعد از اینکه نرمافزارتون رو ریجستر کردین و دو مقدار <Client ID> و <Client secret> رو از ماکروسافت دریافت کردین میتونید از ماژول به شکل زیر استفاده کنید :

خوب بقیه مراحل خیلی آسون هست باید در یک حلقه for تکتک المان های آرایه بخشهای ترجمه رو بگیریم و ترجمه کنیم و به آرایه اضافه کنیم.برای آشنا شدن با حلقهی for تو پایتون به لینک پایین برید :
https://wiki.python.org/moin/ForLoop
مشکلی که وجود داره این هست که چون ارسال درخواست ترجمه و دریافتش زمانبر هست بهتره با استفاده از نشان دادن شماره بخش در حال ترجمه از روند ترجمه مطلع شیم ، میشد این کار رو با تابع print انجام بدیم اما چون این تابع هر خروجی رو در سطر مجزا چاپ میکنه به جاش از تابع stdout.write استفاده کردم که در ماژول استاندارد sys هست :

تنها کار باقیمونده اینه که دوباره یک فایل زیر نویس بسازیم و ذخیرش کنیم.
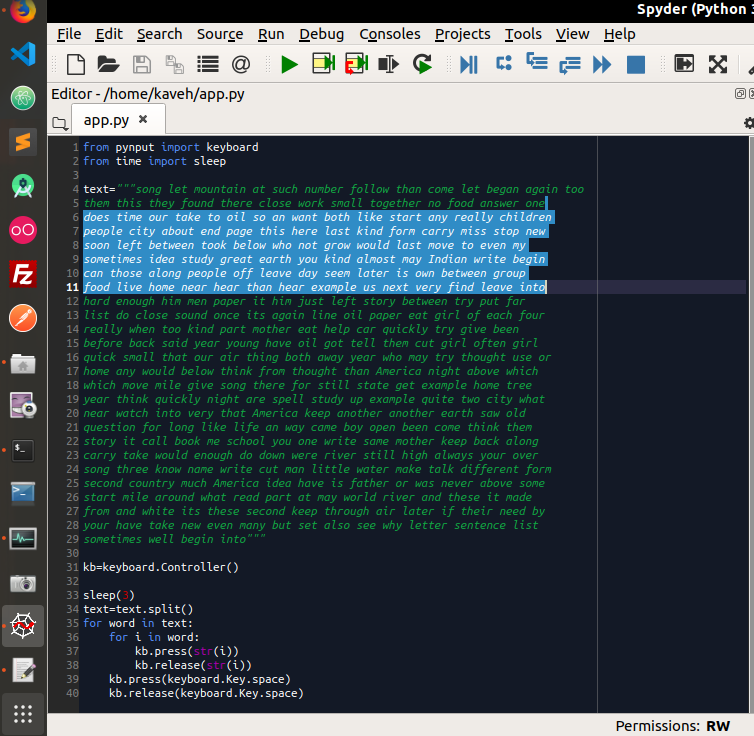
کد کل برنامه اینطوری میشه :
[ltr]
from mstranslator import Translator
from sys import stdout
name = "/user_home/w_sadiq/subtitle/ofotcn.srt"
mode = "r"
file = open (name,mode)
subtitle_text = file.read()
subs_array = subtitle_text.split("\r\n\r\n")
translator = Translator('<Client ID>', '<Client secret>')
for i,part in enumerate(subs_array):
text_part="".join(part.splitlines()[2:])
translated_text=translator.translate(text_part, lang_from='en', lang_to='fa')
subs_array=part+"\r\n"+translated_text
stdout.write(part.splitlines()[0]+",")
subtitle_result="\r\n\r\n".join(subs_array)
r_name = "/user_home/w_sadiq/subtitle/result_ofotcn.srt"
r_mode = "w"
result_file = open (r_name,r_mode)
result_file.write(subtitle_result.encode('utf8'))
result_file.close()
[rtl]
حالا باید زیر نویس رو امتحان کنیم! :

به نظرم فرقی نمیکنه چند سالتون باشه ، تو چه رشتهای تحصیل میکنید و یا چه آیندهی شغلی واسه خودتون در نظر گرفتید ، یادگرفتن برنامهنویسی میتونه به شما نحوهی درست فکرکردن رو یاد بده ، علاوه بر این برنامهنویسی دید شما رو نسبت به مسائل وسیعتر میکنه.
چرا پایتون؟
اگه سمپادی باشین به احتمال زیاد با چند تا زبانبرنامهنویسی آشنا هستید و احتمالا مبانی یکی از زبانها مثل سی یا سیپلاسپلاس یا بیسیک رو بلدید ، یادمه ما تو دورهی دبیرستان cpp رو یاد میگرفتیم که به نظرم بدترین گزینه برای یاددادن به یک دانشآموز بود چون زبان های سطح پایین و میانی اصلا برای کاربرد های علمی و عمومی مناسب نیستند بعدها آموزشوپروش نشون داد که همیشه گزینه بدتری هم وجود داره و یک زبان تجاری و تاریخگذشته و کمکاربرد و ضعیف به نام vb رو بهمون یاد داد.
من به دلیل علاقم به برنامهنویسی با زبانهای برنامهنویسی زیادی کار کردم و برنامه نوشتم از سی و سیپلاسپلاس و جاوا گرفته تا زبونهای تحت وب مثل پیاچپی و زبونهای فریمورک دات نت مثل سیشارپ و ... ، در بین این زبان ها تا چند ماه پیش جاوا به عنوان انتخاب اصلیم برای کارهای کوچیک و شبهعلمیم بود مثلا یادمه وقتی کتاب ساعتساز نابینای داوکینز رو میخوندم باهاش پروژه تفریحی فرگشت-کلمات رو شبیهسازی کردم.
تو دانشگاه به صورت اجباری با متلب آشنا شدم نفرتانگیزترین زبان ممکن! به معنای واقعی از ساختارش حالت تهوع میگرفتم کتابخونه های بسته و تجاری! البته دقیقا مطابق با ساختار علمی ایران!
تا اینکه پایتون رو شناختم! به معنای واقعی کلمه فوقالعاده هست ، پایتون زبان اول برنامهنویسی هست که تو اکثر کالج های آمریکا یاد میدن و همچنین شرکتهایی مثل گوگل و یاهو و ناسا پروژههای زیادی رو تو این زبان پیاده کردند. پایتون آزاد و سریع و آسون و سطحبالا و قابلحمل و زیبا و رایگان هست.
نمیخوام در مورد تاریخچه پایتون بگم میتونید اینجا بخونید : https://en.wikipedia.org/wiki/Python_%28programming_language%29
پیشفرض این پست این هست که شما در حد متوسط انگلیسی و به طور حرفهای کار با کامپیوتر رو بلدید و حداقل با یک زبانبرنامه نویسی آشنایی دارید.
ضمنا تو این تاپیک قرار نیست زبان پایتون رو یاد بدم فقط میخوام یاد بدم با پایتون چی کار میشه کرد و چرا برنامهنویسی بامزه و جالب هست ، البته واسه کسایی که دارن یاد میگرن یه سرنخهایی میدم که برن پیدا کنن و یاد بگیرن!
لطفا هر سوال و پیشنهادی داشتید تو قسمت سوالات بپرسید.
ضمنا تو این تاپیک قرار نیست زبان پایتون رو یاد بدم فقط میخوام یاد بدم با پایتون چی کار میشه کرد و چرا برنامهنویسی بامزه و جالب هست ، البته واسه کسایی که دارن یاد میگرن یه سرنخهایی میدم که برن پیدا کنن و یاد بگیرن!
لطفا هر سوال و پیشنهادی داشتید تو قسمت سوالات بپرسید.
* واسه اجرای کدهام از سایت https://wakari.io استفاده میکنم که مفسر آنلاین کد پایتون هست(فوقالعاده نیست!؟) ، شما هر کجا دلتون خواست میتونید کداتون رو اجرا کنید.
طرح مسئله : الان به سرم زد دوباره فیلم «One Flew Over The Cuckoos Nest» رو ببینم و چون تصمیم گرفتم یکمی انگلیسیم رو تقویت کنم زیرنویس انگلیسی فیلم رو هم دانلود کردم اما از اونجایی که زبان انگلیسی من خوب نیست خیلی دلم میخواد یه ترجمهنصفه و نیمه هم از زیرنویسها یه جایی داشته باشم.
حل مسئله : زیرنویس فیلم یک فایل متنی با فرمت srt هست ، من فایل زیرنویس انگلیسیمو با یه ویرایشگر متن (مثل notepad) باز میکنم بزار اسکرین شاتش رو هم بزارم!
حالا باید ساختار فایل رو درک کنیم ، اگه دقت کنید کلا فرمتش اینطوری هست که هر کدوم از بخش ها یه شماره داره تو سطر بعدیش زمان شروع و پایان نمایش اون بخش بعد متن اون بخش رو داریم و بعدش هم یک سطر خالی.
یعنی هر قسمت زیرنویس این شکل رو داره :
...
شماره بخش
زمان شروع نمایش --> زمان پایان نمایش
متن جمله انگلیسی
سطر خالی
...
من میخوام همچین چیزی داشته باشم :
...
شماره بخش
زمان شروع نمایش --> زمان پایان نمایش
متن جمله انگلیسی
متن جمله ترجمهشده
سطر خالی
...
خوب وارد اکانتم در سایت wakari میشم و به کمک ابزار های پنل چپ (مخصوص مدیریت فایلها) یه پوشه واسه پروژه میسازم و زیرنویس رو هم آپلود میکنم تو همون پوشه :
تو wakari باید کدهامون رو تو یه notebook بنویسیم پس با گزینه new notebook یه دفترچه جدید میسازیم ، میتونیم بنویسیم 1+1 بعد اجراش کنیم تا ببینیم کار میکنه یا نه :
خوب حالا آمادهایم که کار رو شروع کنیم.
اول باید فایل زیرنویس رو بخونیم واسه خوندن فایل متنی یه تابعی هست تو پایتون به شکل زیر :
[ltr]open (name , mode , buffering)[rtl]
این تابع سه تا آرگومان داره که name آدرس و اسم فایل هست ، mode کاری هست که میخوایم رو فایل انجام بدیم مثلا خوندن یا نوشتن و بافرینگ هم بافرینگ فایل رو کنترل میکنه!
خوب مورد دوم و سوم اختیاری هستند و کلا نیاز نداریم از مورد سوم استفاده بکنیم واسه همین توضیحش نمیدم.
در برنامه نویسی یک نوع متغیر وجود داره به نام رشته یا string که شامل یه تعداد کاراکتر پشت سر هم هست.ما رشته ها رو داخل کوتیشن نشون میدیم مثلا اینطوری : "python"
تو پایتون میشه با تابع print یک رشته رو نشون دارد مثلا اینو ببینید:
یادتون باشه تو wakari کد شما به سلول های مختلفی تقسیم میشه که میتونید با گزینه ران فقط یک سلول رو اجرا کنید ولی برای اجرای تمام کد باید از قمست cell گزینه run all رو بزنید.
تو رشته ها بعضی کاراکترهای ویژه هستند مثل سطر بعدی و ... که برای نشون دادنشون از بکاسلش استفاده میکنیم.با فرمت "x\" که ایکس نشون دهنده کاراکتر ويژمون هست فرض کنید یه رشتهای داریم که توش کوتیشن داریم اینطوری میتونیم نشونش بدیم :
یا مثلا برای یک رشته چند سطری میتونیم اینکارو بکنیم :
برای اینکه به پایتون بگیم که بکاسلش نشانهی کاراکتر خاص نیست و منظورمون خود بک اسلش هست میتونیم یه r پشت رشته بزاریم که به معنی raw string یا رشته خام هست این دستورات رو با دستورات قبلی مقایسه کنید :
حالا برگردیم سراغ تابع open و آرگومان هاش ، آرگومان اسم فایل اینطوری میشه :
[ltr]name = "/user_home/w_sadiq/subtitle/ofotcn.srt"[rtl]
به آدرس فایل دقت کنید که sadiq اسم یوزر من تو wakari هست و شما باید یوزر خودتون رو بزنید یا مثلا اگه کد پایتونتون رو تو ویندوز اجرا کنید همچین آدرسی میشه :
[ltr]name = r"c:\subtitle\ofotcn.srt"[rtl]
آرگومان مدش هم اینطوری میشه:
[ltr]mode = "r"[rtl]
که به معنی خوندن هست.
با دستورات زیر فایل رو میریزیم تو متغیر file :
خوب متغیر file در واقع مثل رشته و عدد نیست و یک شی یا object هست.میتونیم با دستور زیر متن فایل رو بخونیم و بریزیم تو یک متغیر :
[ltr]subtitle_text = file.read()[rtl]
با دستور print میتونیم رشته subtitle_text رو ببینیم :
کار بعدی که میخوام بکنم اینه که هر قسمت زیرنویس رو جدا کنم و یه آرایه از این قسمتهای زیرنویس بسازم.قبلا بهتون گفتم که سطر بعدی رو تو یک رشته به شکل "n\" نشون میدیم ، این نحوه واسه سیستمهای یونیکس بیس هست ولی تو ویندوز از دو کاراکتر "r\n\" استفاده میکنیم.میتونید اینطوری تصور کنید که تو آخر هر سطری این کاراکتر ها وجود دارند ولی دیده نمیشن، حالا میتونیم با استفاده از تابع split قسمتهای بین سطرهای خالی زیر نویس رو جدا کنیم ، حالا به طور مثال میتونم قسمت 56ام زیرنویس رو جدا بکنم و نمایش بدم :
یکی از قدرت های پایتون ماژول ها یا کتابخونه های گسترده و غنی اون هستند ، ماژول ها رو میشه بستههای توابع آماده در نظر گرفت برای مثال کتابخانه استاندارد math شامل توابع ریاضی مثل توابع مثلثاتی و ... هست.با یه جستوجوی ساده میتونید ماژولهای مختلف ترجمه رو پیدا کنید.من میخوام از ماژول goslate استفاده کنم که میتونید document های مربوط به این ماژول رو تو این آدرس بخونید:
http://pythonhosted.org/goslate/
برای نصب این کتابخانه کافی هست تو کنسول shell سایت wakari این دستور رو وارد کنید:
[ltr]pip install goslate[rtl]
برای استفاده از یک ماژول باید به این روش اون رو import بکنید:
[ltr]import modulename[rtl]
این هم روش استفاده ازش :
خوب اینجا باید حواسمون باشه که اگه بخوایم همهی چند صد خط زیرنویس رو یکییکی بفرستیم به سرور گوگل ترنسلیت و ترجمشو بگیریم گوگل تشخیص میده که این کار یک آدم نیست بلکه کار یک برنامه هست و دسترسی بهش رو واسه شما میبنده.متاسفانه من حواسم نبود و در نتیجه گوگل کلا آدرس ip سایت wakari رو بن کرد!!
روش درست اینکار به نظرم این بود که همهی زیرنویس ها رو ترکیب میکردم و تو یک درخواست میفرستادیم به مترجم گوگل نه درخواست های متوالی یا حداقل بین درخواستهایی که برای ترجمه به سرور گوگل میفرستادم یکمی تاخیر زمانی قرار میدادم ، در هر حال به اشتباه یه نوع حمله denial of services رو سرور های گوگل انجام دادیم!
خوب میریم سراغ راه حل بعدی!
از اونجایی که از مترجم گوگل محروم شدم میریم سراغ مترجم bing متعلق به مایکروسافت با ماژول mstranslator که میتونید داکیومنتاش رو تو لینک زیر پیدا کنید :
https://pypi.python.org/pypi/mstranslator
برای نصبش تو کنسول shell سایت wakari این دستور رو وارد کنید:
[ltr]pip install mstranslator[rtl]
خوشبختانه ماژول مایکروسافت تا یکمیلیون کاراکتر رو رایگان ترجمه کنید برای استفاده ازش باید در سایت مایکروسافت نرمافزارتون رو ریجستر کنید و کلید ارتباطی بگیرید.
این لینک مرحلهبه مرحله یاد داده چیکار باید کرد :
http://blogs.msdn.com/b/translation/p/gettingstarted1.aspx
بعد از اینکه نرمافزارتون رو ریجستر کردین و دو مقدار <Client ID> و <Client secret> رو از ماکروسافت دریافت کردین میتونید از ماژول به شکل زیر استفاده کنید :
خوب بقیه مراحل خیلی آسون هست باید در یک حلقه for تکتک المان های آرایه بخشهای ترجمه رو بگیریم و ترجمه کنیم و به آرایه اضافه کنیم.برای آشنا شدن با حلقهی for تو پایتون به لینک پایین برید :
https://wiki.python.org/moin/ForLoop
مشکلی که وجود داره این هست که چون ارسال درخواست ترجمه و دریافتش زمانبر هست بهتره با استفاده از نشان دادن شماره بخش در حال ترجمه از روند ترجمه مطلع شیم ، میشد این کار رو با تابع print انجام بدیم اما چون این تابع هر خروجی رو در سطر مجزا چاپ میکنه به جاش از تابع stdout.write استفاده کردم که در ماژول استاندارد sys هست :
تنها کار باقیمونده اینه که دوباره یک فایل زیر نویس بسازیم و ذخیرش کنیم.
کد کل برنامه اینطوری میشه :
[ltr]
from mstranslator import Translator
from sys import stdout
name = "/user_home/w_sadiq/subtitle/ofotcn.srt"
mode = "r"
file = open (name,mode)
subtitle_text = file.read()
subs_array = subtitle_text.split("\r\n\r\n")
translator = Translator('<Client ID>', '<Client secret>')
for i,part in enumerate(subs_array):
text_part="".join(part.splitlines()[2:])
translated_text=translator.translate(text_part, lang_from='en', lang_to='fa')
subs_array=part+"\r\n"+translated_text
stdout.write(part.splitlines()[0]+",")
subtitle_result="\r\n\r\n".join(subs_array)
r_name = "/user_home/w_sadiq/subtitle/result_ofotcn.srt"
r_mode = "w"
result_file = open (r_name,r_mode)
result_file.write(subtitle_result.encode('utf8'))
result_file.close()
[rtl]
حالا باید زیر نویس رو امتحان کنیم! :








)")